EAS弹性Job服务支持训练和推理场景,相较于异步推理服务提供了可复用且能够弹性伸缩的Job服务。在训练场景中,有效解决多个实例(Job)并发执行时,实例(Job)频繁创建和释放导致的资源浪费问题。同时在推理场景能感知每个请求的执行进度,做到更公平的任务调度。本文为您介绍如何使用弹性Job服务。
使用场景
训练场景
弹性Job服务用于训练场景:
功能实现
实现了前后端分离架构,支持部署常驻的前端服务与弹性Job服务。
架构优势
前端服务通常只需较低的资源配置,价格低廉。前端服务常驻可以避免频繁创建前端服务,减少等待时间。后端弹性Job服务支持在一个实例(Job)内循环多次执行训练任务,避免任务在多次执行过程中实例(Job)被反复拉起和释放,提升服务吞吐效率。同时,后端弹性Job服务会在队列长度过长或过短时自动进行扩缩容,保证资源的高效利用。
推理场景
弹性Job服务用于模型推理场景,能够感知每个请求的执行进度,做到更公平的任务调度。
对于响应时间较长的推理服务,一般建议使用EAS异步推理服务的形式来部署,但异步服务存在以下两个问题:
队列服务推送请求时不能保证优先推送给空闲的实例,导致资源不能被充分利用。
服务实例缩容时不能保证当前实例退出时内部请求已处理结束,会导致正在处理的请求被中断,然后被调度到其他实例重新执行。
针对以上问题,弹性Job服务进行了以下处理:
优化了订阅逻辑,保证将请求优先推送到空闲实例。在弹性Job实例退出前会阻塞等待保证当前处理的请求执行结束。
在扩缩容上更加高效,不同于普通监控服务的定期上报机制,弹性Job服务在队列服务内部内置了监控服务,实现了Job场景下专用的监控服务采集链路,保证队列长度超过阈值时能快速触发扩容,将扩缩容的响应时间从分钟级降低到10秒左右。
基本架构
整体框架由队列服务、HPA控制器和弹性Job服务三部分组成,如下图所示。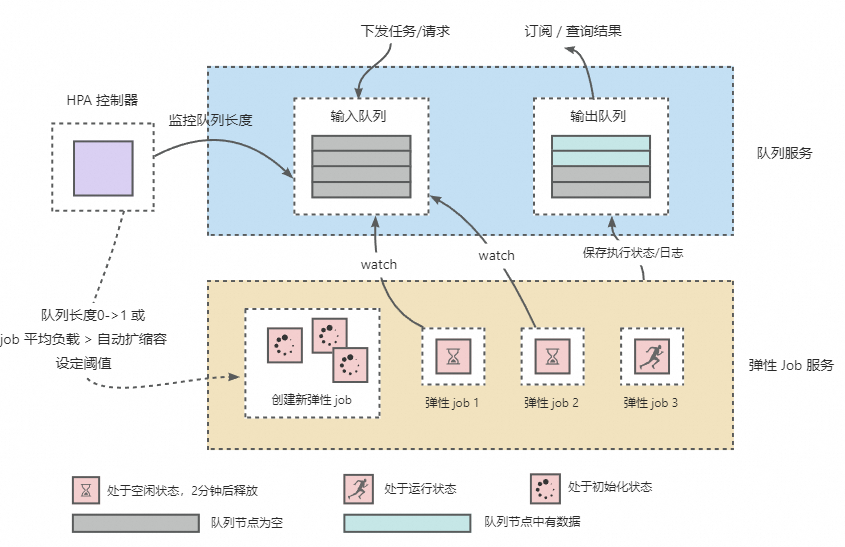
实现逻辑如下:
通过队列服务将请求或任务的下发和执行进行解耦,从而实现同一个弹性Job服务可以执行多个不同请求或任务。
通过HPA控制器来持续监听队列服务中待执行的训练任务和请求的数量,实现对弹性Job服务实例个数的弹性伸缩。其中弹性Job服务自动扩缩容的默认配置如下,更多参数说明,请参见水平自动扩缩容功能。
{ "behavior":{ "onZero":{ "scaleDownGracePeriodSeconds":60 # 缩容到0的生效时间(秒)。 }, "scaleDown":{ "stabilizationWindowSeconds":1 # 缩容的生效时间(秒)。 } }, "max":10, # 实例(Job)的最大个数。 "min":1, # 实例(Job)的最小个数。 "strategies":{ "avg_waiting_length":2 # 每个实例(Job)的平均负载阈值。 } }
服务部署
部署推理服务
类似于创建异步推理服务,参照以下示例内容准备服务配置文件:
{
"containers": [
{
"image": "registry-vpc.cn-shanghai.aliyuncs.com/eas/eas-container-deploy-test:202010091755",
"command": "/data/eas/ENV/bin/python /data/eas/app.py"
"port": 8000,
}
],
"metadata": {
"name": "scalablejob",
"type": "ScalableJob",
"rpc.worker_threads": 4,
"instance": 1,
}
}其中:将type配置为ScalableJob,推理服务就会以弹性Job服务的形式部署。其他参数配置详情,请参见服务模型所有相关参数说明。关于如何部署推理服务,请参见部署写真相机在线推理服务。
服务部署成功后,会自动创建队列服务和弹性Job服务,同时默认启用Autoscaler(水平自动扩缩容)的功能。
部署训练服务
支持集成部署与独立部署两种方式。具体的实现逻辑和配置详情说明如下,具体部署方法,请参见部署弹性伸缩的Kohya训练服务。
实现逻辑
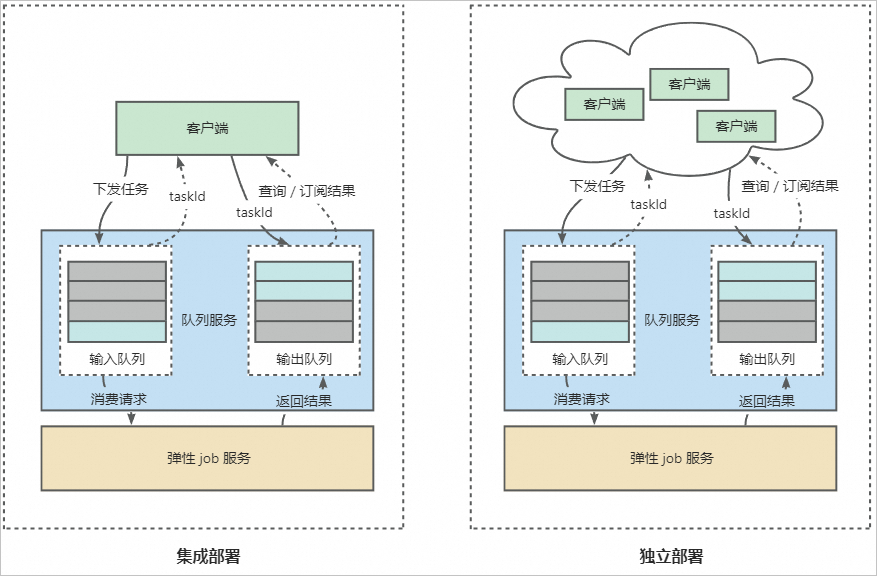
集成部署:EAS除了创建队列服务和弹性Job服务外,还会创建一个前端服务。前端服务主要负责接收用户请求,并将用户请求转发到队列服务中。您可以将前端服务理解成弹性Job服务的客户端。在此模式下,弹性Job服务会被绑定到唯一的前端服务上,此时弹性Job服务只能执行当前前端服务下发的训练任务。
独立部署:独立部署适用于多用户场景,在此模式下弹性Job服务作为公共的后端服务,可以和多个前端服务绑定,每个用户都可以在自己的前端服务下发训练任务,后端Job服务会创建对应的Job实例来执行训练任务,并且每个Job实例可以依次执行不同的训练任务,实现多个用户共享训练资源。不用多次创建训练任务,有效降低使用成本。
配置说明
在部署弹性Job服务时,您需要提供一个自定义镜像环境(kohya场景可以直接使用EAS预置的kohya_ss镜像)。该镜像需包含执行训练任务的所有依赖,只是作为训练任务的执行环境,因此不需要配置启动命令和端口号。如果您需要在训练任务开始前执行一些初始化任务,可以配置初始化命令,EAS会在实例(Job)内部单独创建一个进程来执行初始化任务。如何准备自定义镜像,请参见服务部署:自定义镜像。EAS的预置镜像如下所示:
"containers": [ { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ]集成部署
参照下方示例内容准备服务配置文件,以EAS提供的预置镜像(kohya_ss)为例:
{ "containers": [ { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ], "metadata": { "cpu": 4, "enable_webservice": true, "gpu": 1, "instance": 1, "memory": 15000, "name": "kohya_job", "type": "ScalableJobService" }, "front_end": { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2", "port": 8001, "script": "python -u kohya_gui.py --listen 0.0.0.0 --server_port 8001 --data-dir /workspace --headless --just-ui --job-service" } }其中关键配置说明如下,其他参数配置说明,请参见服务模型所有相关参数说明。
将type配置为ScalableJobService。
前端服务使用的资源组默认和弹性Job服务相同,系统默认分配的资源为2核CPU和8 GB内存。
参考以下示例自定义配置资源组或资源:
{ "front_end": { "resource": "", # 修改前端服务使用专属资源组。 "cpu": 4, "memory": 8000 } }参考以下示例自定义配置部署的机型:
{ "front_end": { "instance_type": "ecs.c6.large" } }
独立部署
参照以下示例准备服务配置文件,以EAS提供的预置镜像(kohya_ss)为例:
{ "containers": [ { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/kohya_ss:2.2" } ], "metadata": { "cpu": 4, "enable_webservice": true, "gpu": 1, "instance": 1, "memory": 15000, "name": "kohya_job", "type": "ScalableJob" } }其中type需要配置为ScalableJob,其他参数配置说明,请参见服务模型所有相关参数说明。
在此模式下,需要用户手动部署前端服务,并且在前端服务内部实现请求的代理,将接收到的请求转发到弹性Job服务的队列内部,完成前端服务和后端Job服务的绑定,详情请参见向队列服务发送数据。
服务调用
为了区分训练场景和推理场景,在调用弹性Job服务时,需要通过设置taskType:command/query来标识。其中:
command:用来标识训练服务。
query:用来标识推理服务。
通过HTTP或SDK调用服务时,需要显式指定taskType,示例如下:
HTTP调用时需要将taskType指定为query。
curl http://166233998075****.cn-shanghai.pai-eas.aliyuncs.com/api/predict/scalablejob?taskType={Wanted_TaskType} -H 'Authorization: xxx' -D 'xxx'SDK调用时需要指定tags,通过该参数来配置taskType。
# 创建输入队列,用于发送任务或请求。 queue_client = QueueClient('166233998075****.cn-shanghai.pai-eas.aliyuncs.com', 'scalabejob') queue_client.set_token('xxx') queue_client.init() tags = {"taskType": "wanted_task_type"} # 向输入队列发送任务或请求。 index, request_id = inputQueue.put(cmd, tags)
获取调用结果:
推理服务:通过EAS队列服务的SDK来获取输出队列的结果,详情请参见队列服务订阅推送。
训练服务:建议部署服务时配置OSS挂载,将训练结果直接保存到OSS路径中做持久化存储,详情请参见部署弹性伸缩的Kohya训练服务。
配置日志收集
EAS弹性Job服务提供了enable_write_log_to_queue配置,通过该配置获取实时日志。
{
"scalable_job": {
"enable_write_log_to_queue": true
}
}在训练场景中,该配置默认开启,系统会将实时日志回写到输出队列,您可以通过EAS队列服务的SDK实时获取训练日志。详情请参见自定义前端服务镜像调用弹性Job服务。
在推理场景中,该配置默认关闭,日志只能通过stdout输出。
相关文档
关于EAS弹性Job服务更详细的使用场景介绍,请参见:
- 本页导读 (1)